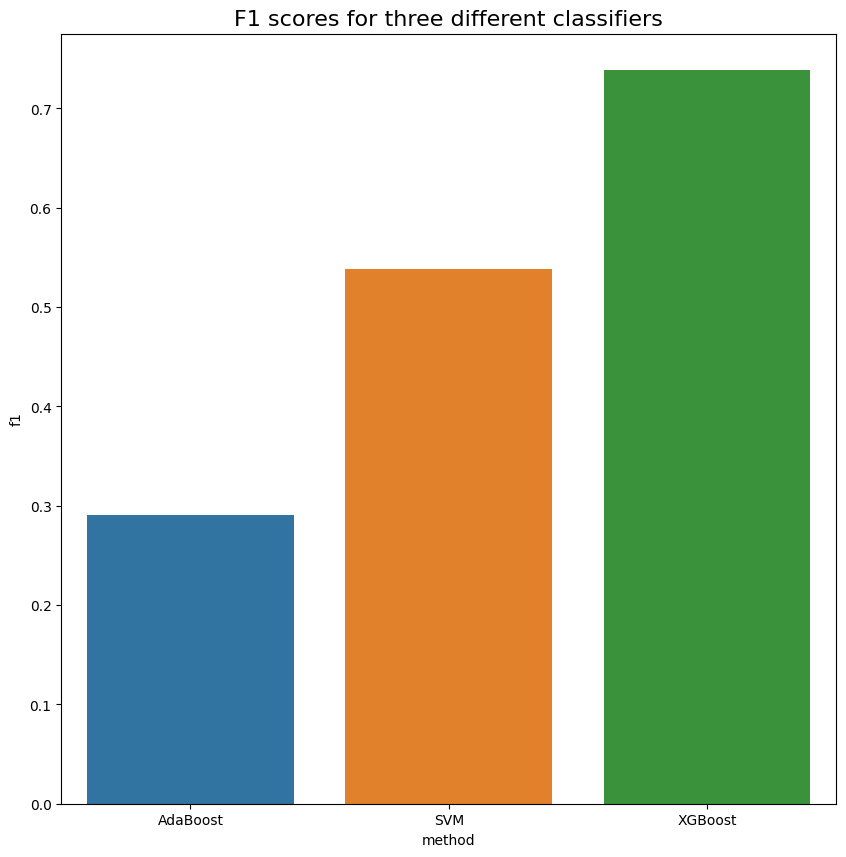
AveragedSubmission(submission_name='baseline_xgboost_tfidf', dataset_name='clarin-pl/polemo2-official', dataset_version='0.0.0', embedding_name='XGBoost+Tfidf', hparams={'max_features': 10000, 'n_estimators': 200, 'max_depth': 7, 'vectorizer': 'TfidfVectorizer'}, packages=['absl-py==1.4.0', 'aiofiles==22.1.0', 'aiohttp==3.8.4', 'aiosignal==1.3.1', 'aiosqlite==0.18.0', 'alembic==1.9.3', 'anyio==3.6.2', 'appdirs==1.4.4', 'argon2-cffi-bindings==21.2.0', 'argon2-cffi==21.3.0', 'arrow==1.2.3', 'asttokens==2.2.1', 'astunparse==1.6.3', 'async-timeout==4.0.2', 'attrs==22.2.0', 'babel==2.11.0', 'backcall==0.2.0', 'beautifulsoup4==4.11.2', 'black==21.12b0', 'bleach==6.0.0', 'cachetools==5.3.0', 'catalogue==2.0.8', 'certifi==2022.12.7', 'cffi==1.15.1', 'charset-normalizer==3.0.1', 'click==8.0.4', 'cmaes==0.9.1', 'colorlog==6.7.0', 'comm==0.1.2', 'contourpy==1.0.7', 'coverage==6.2', 'cycler==0.11.0', 'datasets==2.9.0', 'debugpy==1.6.6', 'decorator==5.1.1', 'defusedxml==0.7.1', 'dill==0.3.6', 'docker-pycreds==0.4.0', 'execnb==0.1.5', 'executing==1.2.0', 'fastcore==1.5.28', 'fastjsonschema==2.16.2', 'filelock==3.9.0', 'fonttools==4.38.0', 'fqdn==1.5.1', 'frozenlist==1.3.3', 'fsspec==2023.1.0', 'future==0.18.3', 'ghapi==1.0.3', 'gitdb==4.0.10', 'gitpython==3.1.30', 'google-auth-oauthlib==0.4.6', 'google-auth==2.16.0', 'greenlet==2.0.2', 'grpcio==1.51.1', 'huggingface-hub==0.12.0', 'idna==3.4', 'importlib-metadata==6.0.0', 'iniconfig==2.0.0', 'ipykernel==6.21.2', 'ipython-genutils==0.2.0', 'ipython==8.10.0', 'isoduration==20.11.0', 'isort==5.10.1', 'jedi==0.18.2', 'jinja2==3.1.2', 'joblib==1.2.0', 'json5==0.9.11', 'jsonpointer==2.3', 'jsonschema==4.17.3', 'jupyter-client==8.0.2', 'jupyter-core==5.2.0', 'jupyter-events==0.5.0', 'jupyter-server-fileid==0.6.0', 'jupyter-server-terminals==0.4.4', 'jupyter-server-ydoc==0.6.1', 'jupyter-server==2.2.1', 'jupyter-ydoc==0.2.2', 'jupyterlab-pygments==0.2.2', 'jupyterlab-server==2.19.0', 'jupyterlab==3.6.1', 'kiwisolver==1.4.4', 'mako==1.2.4', 'markdown==3.4.1', 'markupsafe==2.1.2', 'matplotlib-inline==0.1.6', 'matplotlib==3.6.3', 'mistune==2.0.5', 'multidict==6.0.4', 'multiprocess==0.70.14', 'mypy-extensions==1.0.0', 'mypy==0.991', 'nbclassic==0.5.1', 'nbclient==0.7.2', 'nbconvert==7.2.9', 'nbdev==2.3.11', 'nbformat==5.7.3', 'nest-asyncio==1.5.6', 'notebook-shim==0.2.2', 'notebook==6.5.2', 'numpy==1.23.4', 'oauthlib==3.2.2', 'optuna==3.1.0', 'packaging==23.0', 'pandas==1.5.3', 'pandocfilters==1.5.0', 'parso==0.8.3', 'pastel==0.2.1', 'pathspec==0.11.0', 'pathtools==0.1.2', 'pexpect==4.8.0', 'pickleshare==0.7.5', 'pillow==9.4.0', 'pip==23.0', 'platformdirs==3.0.0', 'pluggy==1.0.0', 'poethepoet==0.11.0', 'prometheus-client==0.16.0', 'prompt-toolkit==3.0.36', 'protobuf==4.21.12', 'psutil==5.9.4', 'ptyprocess==0.7.0', 'pure-eval==0.2.2', 'py==1.11.0', 'pyarrow==11.0.0', 'pyasn1-modules==0.2.8', 'pyasn1==0.4.8', 'pycparser==2.21', 'pydantic==1.10.4', 'pydeprecate==0.3.1', 'pyflakes==2.4.0', 'pygments==2.14.0', 'pyparsing==3.0.9', 'pyrsistent==0.19.3', 'pytest-env==0.6.2', 'pytest==6.2.5', 'python-dateutil==2.8.2', 'python-json-logger==2.0.5', 'pytorch-lightning==1.5.4', 'pytz==2022.7.1', 'pyyaml==6.0', 'pyzmq==25.0.0', 'regex==2022.10.31', 'requests-oauthlib==1.3.1', 'requests==2.28.2', 'responses==0.18.0', 'rfc3339-validator==0.1.4', 'rfc3986-validator==0.1.1', 'rsa==4.9', 'sacremoses==0.0.53', 'scikit-learn==1.2.1', 'scipy==1.9.3', 'seaborn==0.12.2', 'send2trash==1.8.0', 'sentry-sdk==1.15.0', 'seqeval==1.2.2', 'setproctitle==1.3.2', 'setuptools==65.7.0', 'six==1.16.0', 'smmap==5.0.0', 'sniffio==1.3.0', 'soupsieve==2.3.2.post1', 'sqlalchemy==2.0.3', 'srsly==2.4.5', 'stack-data==0.6.2', 'tensorboard-data-server==0.7.0', 'tensorboard-plugin-wit==1.8.1', 'tensorboard==2.12.0', 'terminado==0.17.1', 'threadpoolctl==3.1.0', 'tinycss2==1.2.1', 'tokenize-rt==5.0.0', 'tokenizers==0.13.2', 'toml==0.10.2', 'tomli==1.2.3', 'torch==1.12.1+cu113', 'torchaudio==0.12.1+cu113', 'torchmetrics==0.11.1', 'torchvision==0.13.1+cu113', 'tornado==6.2', 'tqdm==4.64.1', 'traitlets==5.9.0', 'transformers==4.26.1', 'typer==0.7.0', 'types-docutils==0.19.1.3', 'types-pyyaml==6.0.12.6', 'types-requests==2.26.1', 'types-setuptools==67.2.0.1', 'typing-extensions==4.4.0', 'uri-template==1.2.0', 'urllib3==1.26.14', 'wandb==0.13.10', 'watchdog==2.2.1', 'wcwidth==0.2.6', 'webcolors==1.12', 'webencodings==0.5.1', 'websocket-client==1.5.1', 'werkzeug==2.2.2', 'wheel==0.38.4', 'xgboost==1.7.3', 'xxhash==3.2.0', 'y-py==0.5.5', 'yarl==1.8.2', 'ypy-websocket==0.8.2', 'zipp==3.13.0'], predictions=[Predictions(y_pred=array([1, 3, 2, 2, 3, 0, 0, 0, 1, 3, 1, 0, 2, 2, 2, 1, 1, 1, 1, 1, 1, 2,
2, 3, 1, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1, 3, 2, 3, 1, 1, 2, 1, 1, 3,
0, 1, 1, 0, 1, 1, 2, 0, 2, 2, 1, 2, 2, 1, 2, 2, 2, 3, 3, 2, 0, 1,
0, 1, 0, 2, 2, 1, 2, 1, 1, 2, 1, 2, 2, 0, 2, 3, 1, 1, 1, 2, 1, 1,
3, 1, 0, 1, 2, 3, 1, 1, 2, 1, 3, 2, 3, 0, 1, 1, 2, 3, 2, 2, 2, 3,
1, 1, 1, 3, 1, 0, 2, 1, 0, 3, 0, 2, 3, 1, 2, 1, 1, 2, 2, 0, 2, 2,
1, 1, 0, 2, 1, 2, 1, 0, 2, 1, 1, 3, 1, 2, 1, 0, 1, 1, 1, 0, 1, 1,
1, 1, 2, 2, 2, 1, 0, 3, 1, 1, 1, 3, 3, 0, 1, 1, 1, 1, 1, 2, 1, 1,
3, 0, 1, 1, 1, 1, 0, 1, 2, 1, 1, 1, 2, 3, 1, 1, 2, 2, 1, 1, 2, 1,
0, 2, 2, 1, 1, 0, 1, 1, 2, 3, 0, 2, 0, 0, 1, 1, 0, 1, 1, 2, 1, 1,
1, 1, 1, 2, 1, 2, 1, 1, 1, 3, 1, 2, 2, 3, 1, 1, 3, 2, 1, 1, 2, 3,
2, 1, 3, 3, 1, 1, 3, 2, 2, 2, 2, 3, 1, 2, 3, 0, 2, 2, 3, 0, 1, 1,
1, 3, 0, 1, 1, 2, 1, 1, 0, 1, 3, 2, 1, 1, 1, 1, 1, 3, 1, 3, 1, 3,
0, 3, 2, 1, 2, 2, 1, 3, 2, 2, 1, 1, 2, 3, 1, 0, 2, 1, 2, 1, 2, 3,
3, 3, 1, 0, 1, 0, 1, 0, 3, 0, 3, 0, 2, 1, 1, 3, 1, 1, 1, 2, 2, 0,
1, 1, 3, 0, 2, 0, 1, 3, 2, 0, 2, 1, 3, 1, 1, 2, 1, 1, 2, 1, 2, 2,
1, 0, 2, 1, 1, 0, 1, 1, 1, 3, 2, 3, 2, 1, 1, 1, 2, 1, 3, 2, 0, 3,
2, 1, 2, 1, 2, 1, 2, 2, 1, 3, 1, 2, 2, 1, 0, 3, 1, 1, 0, 1, 1, 0,
2, 3, 0, 0, 0, 2, 3, 1, 1, 3, 3, 2, 1, 3, 1, 1, 1, 1, 1, 3, 0, 1,
2, 3, 2, 1, 3, 2, 2, 1, 1, 1, 0, 1, 3, 0, 1, 1, 1, 2, 1, 2, 2, 0,
1, 0, 1, 2, 1, 1, 2, 2, 1, 1, 1, 3, 1, 1, 1, 1, 0, 1, 3, 3, 1, 2,
1, 3, 1, 3, 1, 2, 2, 0, 0, 2, 2, 0, 1, 2, 2, 1, 3, 2, 3, 1, 1, 1,
1, 2, 0, 3, 0, 1, 1, 0, 2, 1, 3, 1, 1, 1, 0, 1, 1, 2, 1, 2, 2, 1,
0, 1, 2, 0, 3, 2, 0, 0, 1, 2, 1, 3, 1, 2, 3, 2, 2, 0, 3, 1, 2, 1,
2, 2, 1, 2, 1, 1, 0, 2, 1, 1, 1, 1, 2, 1, 2, 1, 2, 3, 1, 2, 2, 2,
1, 2, 1, 0, 2, 2, 1, 1, 0, 1, 2, 1, 0, 1, 2, 1, 3, 1, 1, 2, 1, 1,
0, 1, 2, 1, 1, 3, 2, 0, 2, 1, 3, 1, 1, 2, 1, 2, 1, 2, 3, 1, 2, 1,
1, 1, 0, 0, 0, 3, 1, 2, 1, 1, 1, 0, 2, 1, 2, 0, 1, 3, 2, 1, 3, 2,
2, 2, 3, 2, 2, 1, 1, 2, 1, 1, 2, 1, 1, 0, 1, 3, 1, 0, 1, 1, 3, 3,
1, 0, 2, 2, 3, 2, 1, 1, 2, 1, 2, 1, 1, 0, 1, 1, 1, 2, 3, 2, 2, 1,
2, 0, 2, 1, 1, 1, 1, 3, 2, 1, 1, 1, 1, 1, 2, 1, 0, 2, 1, 2, 1, 1,
2, 3, 1, 1, 1, 2, 1, 2, 0, 1, 0, 1, 2, 1, 2, 1, 1, 1, 1, 2, 0, 1,
2, 1, 1, 1, 2, 1, 3, 2, 1, 1, 0, 0, 3, 2, 1, 1, 2, 1, 0, 3, 1, 2,
1, 1, 3, 1, 1, 3, 0, 1, 1, 3, 1, 0, 3, 2, 1, 1, 3, 2, 2, 1, 1, 1,
1, 3, 1, 0, 2, 0, 1, 2, 2, 1, 1, 1, 0, 1, 1, 0, 2, 0, 3, 1, 1, 2,
1, 1, 1, 1, 3, 1, 3, 3, 1, 3, 1, 1, 0, 1, 2, 2, 2, 1, 2, 0, 2, 3,
2, 1, 1, 2, 1, 2, 1, 1, 2, 1, 1, 3, 1, 1, 2, 1, 1, 0, 0, 2, 1, 2,
3, 0, 1, 1, 2, 1]), y_true=array([1, 2, 2, 2, 2, 0, 0, 0, 1, 3, 1, 0, 2, 2, 2, 1, 1, 1, 1, 3, 3, 2,
2, 3, 1, 2, 1, 1, 1, 1, 3, 2, 2, 1, 1, 3, 2, 1, 1, 2, 2, 1, 1, 2,
0, 1, 1, 0, 1, 1, 2, 0, 2, 2, 1, 2, 2, 1, 2, 1, 0, 3, 3, 1, 0, 3,
0, 1, 0, 2, 2, 1, 1, 1, 1, 2, 1, 2, 2, 0, 2, 1, 1, 1, 1, 2, 3, 3,
2, 3, 1, 2, 2, 2, 1, 1, 2, 1, 3, 2, 1, 0, 1, 1, 2, 3, 3, 2, 2, 3,
1, 1, 1, 3, 1, 0, 2, 1, 0, 3, 0, 3, 3, 1, 2, 1, 1, 1, 2, 0, 2, 2,
1, 1, 0, 2, 1, 3, 3, 0, 2, 1, 1, 2, 1, 2, 1, 0, 1, 1, 1, 0, 1, 1,
1, 1, 2, 2, 2, 1, 0, 3, 1, 1, 1, 2, 3, 0, 1, 2, 1, 1, 1, 0, 1, 1,
3, 0, 1, 3, 1, 1, 0, 2, 2, 2, 1, 1, 2, 3, 1, 2, 2, 2, 1, 1, 2, 1,
0, 3, 2, 3, 1, 0, 2, 1, 2, 3, 0, 2, 0, 0, 1, 1, 0, 1, 1, 2, 1, 1,
1, 1, 3, 1, 1, 2, 2, 1, 1, 2, 2, 3, 2, 3, 1, 3, 1, 3, 1, 3, 2, 3,
2, 2, 2, 3, 1, 1, 1, 1, 2, 2, 2, 3, 1, 2, 1, 0, 2, 2, 2, 0, 1, 1,
1, 3, 0, 1, 3, 2, 3, 1, 0, 1, 3, 3, 2, 3, 1, 1, 1, 2, 1, 2, 0, 1,
0, 3, 2, 1, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 1, 0, 2, 1, 2, 1, 1, 3,
3, 2, 3, 0, 3, 0, 1, 0, 3, 0, 3, 0, 1, 1, 1, 3, 1, 3, 1, 3, 0, 0,
1, 1, 3, 0, 2, 0, 1, 2, 2, 0, 1, 1, 3, 2, 1, 2, 3, 3, 2, 3, 2, 2,
1, 0, 2, 1, 1, 1, 1, 1, 1, 3, 3, 3, 2, 1, 1, 3, 2, 1, 3, 2, 0, 1,
2, 1, 1, 2, 2, 1, 2, 2, 0, 1, 1, 2, 2, 2, 0, 3, 1, 1, 0, 1, 1, 0,
2, 3, 0, 0, 0, 2, 3, 1, 1, 1, 3, 2, 1, 1, 1, 1, 1, 1, 1, 2, 0, 1,
2, 1, 2, 1, 3, 3, 2, 1, 1, 1, 0, 3, 3, 0, 1, 1, 3, 2, 1, 2, 3, 0,
2, 0, 1, 3, 1, 1, 2, 2, 2, 1, 1, 3, 1, 3, 1, 1, 0, 1, 1, 2, 1, 2,
1, 2, 1, 2, 1, 2, 2, 0, 0, 2, 2, 0, 1, 3, 1, 1, 2, 2, 2, 1, 3, 1,
1, 3, 0, 2, 0, 1, 1, 0, 2, 1, 1, 1, 1, 1, 0, 1, 1, 2, 1, 1, 3, 1,
0, 2, 2, 0, 1, 2, 0, 0, 1, 2, 1, 1, 1, 1, 2, 2, 1, 0, 3, 1, 2, 1,
3, 2, 1, 2, 1, 1, 0, 0, 1, 1, 1, 1, 3, 0, 3, 2, 2, 2, 3, 2, 0, 3,
1, 2, 1, 0, 2, 3, 1, 1, 0, 1, 3, 1, 0, 1, 2, 3, 1, 1, 3, 3, 1, 1,
0, 1, 0, 3, 1, 3, 1, 0, 2, 1, 2, 2, 1, 2, 1, 2, 1, 2, 2, 1, 2, 1,
2, 1, 0, 0, 0, 1, 1, 2, 1, 1, 1, 0, 2, 3, 2, 0, 3, 2, 2, 1, 3, 2,
2, 1, 1, 3, 2, 2, 3, 2, 1, 1, 3, 1, 1, 0, 1, 1, 2, 0, 1, 1, 1, 1,
1, 2, 1, 2, 3, 3, 3, 2, 2, 3, 2, 1, 1, 0, 1, 1, 1, 2, 2, 3, 2, 1,
1, 0, 2, 1, 2, 1, 1, 3, 2, 1, 1, 1, 1, 1, 2, 1, 0, 2, 1, 2, 3, 1,
2, 3, 1, 1, 1, 2, 1, 2, 0, 1, 0, 3, 2, 3, 2, 1, 1, 3, 1, 1, 0, 1,
2, 3, 1, 3, 1, 1, 3, 1, 1, 3, 0, 0, 3, 2, 3, 1, 2, 1, 0, 2, 0, 2,
1, 1, 3, 1, 2, 3, 0, 1, 1, 3, 1, 0, 3, 2, 1, 1, 3, 2, 2, 1, 1, 1,
1, 3, 1, 0, 2, 0, 0, 1, 3, 3, 1, 3, 0, 1, 1, 0, 2, 0, 3, 1, 1, 2,
1, 2, 1, 1, 3, 1, 3, 3, 1, 1, 1, 1, 0, 1, 2, 2, 2, 1, 2, 0, 2, 2,
2, 1, 1, 2, 1, 2, 2, 1, 3, 0, 0, 3, 1, 1, 2, 1, 3, 0, 0, 2, 3, 2,
2, 0, 1, 3, 2, 2]), y_probabilities=None, names=None), Predictions(y_pred=array([1, 3, 2, 2, 3, 0, 0, 0, 1, 3, 1, 0, 2, 2, 2, 1, 1, 1, 1, 1, 1, 2,
2, 3, 1, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1, 3, 2, 3, 1, 1, 2, 1, 1, 3,
0, 1, 1, 0, 1, 1, 2, 0, 2, 2, 1, 2, 2, 1, 2, 2, 2, 3, 3, 2, 0, 1,
0, 1, 0, 2, 2, 1, 2, 1, 1, 2, 1, 2, 2, 0, 2, 3, 1, 1, 1, 2, 1, 1,
3, 1, 0, 1, 2, 3, 1, 1, 2, 1, 3, 2, 3, 0, 1, 1, 2, 3, 2, 2, 2, 3,
1, 1, 1, 3, 1, 0, 2, 1, 0, 3, 0, 2, 3, 1, 2, 1, 1, 2, 2, 0, 2, 2,
1, 1, 0, 2, 1, 2, 1, 0, 2, 1, 1, 3, 1, 2, 1, 0, 1, 1, 1, 0, 1, 1,
1, 1, 2, 2, 2, 1, 0, 3, 1, 1, 1, 3, 3, 0, 1, 1, 1, 1, 1, 2, 1, 1,
3, 0, 1, 1, 1, 1, 0, 1, 2, 1, 1, 1, 2, 3, 1, 1, 2, 2, 1, 1, 2, 1,
0, 2, 2, 1, 1, 0, 1, 1, 2, 3, 0, 2, 0, 0, 1, 1, 0, 1, 1, 2, 1, 1,
1, 1, 1, 2, 1, 2, 1, 1, 1, 3, 1, 2, 2, 3, 1, 1, 3, 2, 1, 1, 2, 3,
2, 1, 3, 3, 1, 1, 3, 2, 2, 2, 2, 3, 1, 2, 3, 0, 2, 2, 3, 0, 1, 1,
1, 3, 0, 1, 1, 2, 1, 1, 0, 1, 3, 2, 1, 1, 1, 1, 1, 3, 1, 3, 1, 3,
0, 3, 2, 1, 2, 2, 1, 3, 2, 2, 1, 1, 2, 3, 1, 0, 2, 1, 2, 1, 2, 3,
3, 3, 1, 0, 1, 0, 1, 0, 3, 0, 3, 0, 2, 1, 1, 3, 1, 1, 1, 2, 2, 0,
1, 1, 3, 0, 2, 0, 1, 3, 2, 0, 2, 1, 3, 1, 1, 2, 1, 1, 2, 1, 2, 2,
1, 0, 2, 1, 1, 0, 1, 1, 1, 3, 2, 3, 2, 1, 1, 1, 2, 1, 3, 2, 0, 3,
2, 1, 2, 1, 2, 1, 2, 2, 1, 3, 1, 2, 2, 1, 0, 3, 1, 1, 0, 1, 1, 0,
2, 3, 0, 0, 0, 2, 3, 1, 1, 3, 3, 2, 1, 3, 1, 1, 1, 1, 1, 3, 0, 1,
2, 3, 2, 1, 3, 2, 2, 1, 1, 1, 0, 1, 3, 0, 1, 1, 1, 2, 1, 2, 2, 0,
1, 0, 1, 2, 1, 1, 2, 2, 1, 1, 1, 3, 1, 1, 1, 1, 0, 1, 3, 3, 1, 2,
1, 3, 1, 3, 1, 2, 2, 0, 0, 2, 2, 0, 1, 2, 2, 1, 3, 2, 3, 1, 1, 1,
1, 2, 0, 3, 0, 1, 1, 0, 2, 1, 3, 1, 1, 1, 0, 1, 1, 2, 1, 2, 2, 1,
0, 1, 2, 0, 3, 2, 0, 0, 1, 2, 1, 3, 1, 2, 3, 2, 2, 0, 3, 1, 2, 1,
2, 2, 1, 2, 1, 1, 0, 2, 1, 1, 1, 1, 2, 1, 2, 1, 2, 3, 1, 2, 2, 2,
1, 2, 1, 0, 2, 2, 1, 1, 0, 1, 2, 1, 0, 1, 2, 1, 3, 1, 1, 2, 1, 1,
0, 1, 2, 1, 1, 3, 2, 0, 2, 1, 3, 1, 1, 2, 1, 2, 1, 2, 3, 1, 2, 1,
1, 1, 0, 0, 0, 3, 1, 2, 1, 1, 1, 0, 2, 1, 2, 0, 1, 3, 2, 1, 3, 2,
2, 2, 3, 2, 2, 1, 1, 2, 1, 1, 2, 1, 1, 0, 1, 3, 1, 0, 1, 1, 3, 3,
1, 0, 2, 2, 3, 2, 1, 1, 2, 1, 2, 1, 1, 0, 1, 1, 1, 2, 3, 2, 2, 1,
2, 0, 2, 1, 1, 1, 1, 3, 2, 1, 1, 1, 1, 1, 2, 1, 0, 2, 1, 2, 1, 1,
2, 3, 1, 1, 1, 2, 1, 2, 0, 1, 0, 1, 2, 1, 2, 1, 1, 1, 1, 2, 0, 1,
2, 1, 1, 1, 2, 1, 3, 2, 1, 1, 0, 0, 3, 2, 1, 1, 2, 1, 0, 3, 1, 2,
1, 1, 3, 1, 1, 3, 0, 1, 1, 3, 1, 0, 3, 2, 1, 1, 3, 2, 2, 1, 1, 1,
1, 3, 1, 0, 2, 0, 1, 2, 2, 1, 1, 1, 0, 1, 1, 0, 2, 0, 3, 1, 1, 2,
1, 1, 1, 1, 3, 1, 3, 3, 1, 3, 1, 1, 0, 1, 2, 2, 2, 1, 2, 0, 2, 3,
2, 1, 1, 2, 1, 2, 1, 1, 2, 1, 1, 3, 1, 1, 2, 1, 1, 0, 0, 2, 1, 2,
3, 0, 1, 1, 2, 1]), y_true=array([1, 2, 2, 2, 2, 0, 0, 0, 1, 3, 1, 0, 2, 2, 2, 1, 1, 1, 1, 3, 3, 2,
2, 3, 1, 2, 1, 1, 1, 1, 3, 2, 2, 1, 1, 3, 2, 1, 1, 2, 2, 1, 1, 2,
0, 1, 1, 0, 1, 1, 2, 0, 2, 2, 1, 2, 2, 1, 2, 1, 0, 3, 3, 1, 0, 3,
0, 1, 0, 2, 2, 1, 1, 1, 1, 2, 1, 2, 2, 0, 2, 1, 1, 1, 1, 2, 3, 3,
2, 3, 1, 2, 2, 2, 1, 1, 2, 1, 3, 2, 1, 0, 1, 1, 2, 3, 3, 2, 2, 3,
1, 1, 1, 3, 1, 0, 2, 1, 0, 3, 0, 3, 3, 1, 2, 1, 1, 1, 2, 0, 2, 2,
1, 1, 0, 2, 1, 3, 3, 0, 2, 1, 1, 2, 1, 2, 1, 0, 1, 1, 1, 0, 1, 1,
1, 1, 2, 2, 2, 1, 0, 3, 1, 1, 1, 2, 3, 0, 1, 2, 1, 1, 1, 0, 1, 1,
3, 0, 1, 3, 1, 1, 0, 2, 2, 2, 1, 1, 2, 3, 1, 2, 2, 2, 1, 1, 2, 1,
0, 3, 2, 3, 1, 0, 2, 1, 2, 3, 0, 2, 0, 0, 1, 1, 0, 1, 1, 2, 1, 1,
1, 1, 3, 1, 1, 2, 2, 1, 1, 2, 2, 3, 2, 3, 1, 3, 1, 3, 1, 3, 2, 3,
2, 2, 2, 3, 1, 1, 1, 1, 2, 2, 2, 3, 1, 2, 1, 0, 2, 2, 2, 0, 1, 1,
1, 3, 0, 1, 3, 2, 3, 1, 0, 1, 3, 3, 2, 3, 1, 1, 1, 2, 1, 2, 0, 1,
0, 3, 2, 1, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 1, 0, 2, 1, 2, 1, 1, 3,
3, 2, 3, 0, 3, 0, 1, 0, 3, 0, 3, 0, 1, 1, 1, 3, 1, 3, 1, 3, 0, 0,
1, 1, 3, 0, 2, 0, 1, 2, 2, 0, 1, 1, 3, 2, 1, 2, 3, 3, 2, 3, 2, 2,
1, 0, 2, 1, 1, 1, 1, 1, 1, 3, 3, 3, 2, 1, 1, 3, 2, 1, 3, 2, 0, 1,
2, 1, 1, 2, 2, 1, 2, 2, 0, 1, 1, 2, 2, 2, 0, 3, 1, 1, 0, 1, 1, 0,
2, 3, 0, 0, 0, 2, 3, 1, 1, 1, 3, 2, 1, 1, 1, 1, 1, 1, 1, 2, 0, 1,
2, 1, 2, 1, 3, 3, 2, 1, 1, 1, 0, 3, 3, 0, 1, 1, 3, 2, 1, 2, 3, 0,
2, 0, 1, 3, 1, 1, 2, 2, 2, 1, 1, 3, 1, 3, 1, 1, 0, 1, 1, 2, 1, 2,
1, 2, 1, 2, 1, 2, 2, 0, 0, 2, 2, 0, 1, 3, 1, 1, 2, 2, 2, 1, 3, 1,
1, 3, 0, 2, 0, 1, 1, 0, 2, 1, 1, 1, 1, 1, 0, 1, 1, 2, 1, 1, 3, 1,
0, 2, 2, 0, 1, 2, 0, 0, 1, 2, 1, 1, 1, 1, 2, 2, 1, 0, 3, 1, 2, 1,
3, 2, 1, 2, 1, 1, 0, 0, 1, 1, 1, 1, 3, 0, 3, 2, 2, 2, 3, 2, 0, 3,
1, 2, 1, 0, 2, 3, 1, 1, 0, 1, 3, 1, 0, 1, 2, 3, 1, 1, 3, 3, 1, 1,
0, 1, 0, 3, 1, 3, 1, 0, 2, 1, 2, 2, 1, 2, 1, 2, 1, 2, 2, 1, 2, 1,
2, 1, 0, 0, 0, 1, 1, 2, 1, 1, 1, 0, 2, 3, 2, 0, 3, 2, 2, 1, 3, 2,
2, 1, 1, 3, 2, 2, 3, 2, 1, 1, 3, 1, 1, 0, 1, 1, 2, 0, 1, 1, 1, 1,
1, 2, 1, 2, 3, 3, 3, 2, 2, 3, 2, 1, 1, 0, 1, 1, 1, 2, 2, 3, 2, 1,
1, 0, 2, 1, 2, 1, 1, 3, 2, 1, 1, 1, 1, 1, 2, 1, 0, 2, 1, 2, 3, 1,
2, 3, 1, 1, 1, 2, 1, 2, 0, 1, 0, 3, 2, 3, 2, 1, 1, 3, 1, 1, 0, 1,
2, 3, 1, 3, 1, 1, 3, 1, 1, 3, 0, 0, 3, 2, 3, 1, 2, 1, 0, 2, 0, 2,
1, 1, 3, 1, 2, 3, 0, 1, 1, 3, 1, 0, 3, 2, 1, 1, 3, 2, 2, 1, 1, 1,
1, 3, 1, 0, 2, 0, 0, 1, 3, 3, 1, 3, 0, 1, 1, 0, 2, 0, 3, 1, 1, 2,
1, 2, 1, 1, 3, 1, 3, 3, 1, 1, 1, 1, 0, 1, 2, 2, 2, 1, 2, 0, 2, 2,
2, 1, 1, 2, 1, 2, 2, 1, 3, 0, 0, 3, 1, 1, 2, 1, 3, 0, 0, 2, 3, 2,
2, 0, 1, 3, 2, 2]), y_probabilities=None, names=None)], config=None, dataset_key='polemo2', leaderboard_task_name=<LeaderboardTask.sentiment_analysis: 'Sentiment Analysis'>, metrics=[{'accuracy': 0.7573170731707317, 'f1_macro': 0.7383632851951776, 'f1_micro': 0.7573170731707317, 'f1_weighted': 0.7531105273460682, 'recall_macro': 0.7279708041839421, 'recall_micro': 0.7573170731707317, 'recall_weighted': 0.7573170731707317, 'precision_macro': 0.7527270564328854, 'precision_micro': 0.7573170731707317, 'precision_weighted': 0.7526286151229844, 'classes': {0: {'precision': 0.9722222222222222, 'recall': 0.8898305084745762, 'f1': 0.9292035398230089, 'support': 118}, 1: {'precision': 0.7745358090185677, 'recall': 0.8613569321533924, 'f1': 0.8156424581005588, 'support': 339}, 2: {'precision': 0.746606334841629, 'recall': 0.7268722466960352, 'f1': 0.7366071428571428, 'support': 227}, 3: {'precision': 0.5175438596491229, 'recall': 0.4338235294117647, 'f1': 0.47200000000000003, 'support': 136}}}, {'accuracy': 0.7573170731707317, 'f1_macro': 0.7383632851951776, 'f1_micro': 0.7573170731707317, 'f1_weighted': 0.7531105273460682, 'recall_macro': 0.7279708041839421, 'recall_micro': 0.7573170731707317, 'recall_weighted': 0.7573170731707317, 'precision_macro': 0.7527270564328854, 'precision_micro': 0.7573170731707317, 'precision_weighted': 0.7526286151229844, 'classes': {0: {'precision': 0.9722222222222222, 'recall': 0.8898305084745762, 'f1': 0.9292035398230089, 'support': 118}, 1: {'precision': 0.7745358090185677, 'recall': 0.8613569321533924, 'f1': 0.8156424581005588, 'support': 339}, 2: {'precision': 0.746606334841629, 'recall': 0.7268722466960352, 'f1': 0.7366071428571428, 'support': 227}, 3: {'precision': 0.5175438596491229, 'recall': 0.4338235294117647, 'f1': 0.47200000000000003, 'support': 136}}}], metrics_avg={'accuracy': 0.7573170731707317, 'f1_macro': 0.7383632851951776, 'f1_micro': 0.7573170731707317, 'f1_weighted': 0.7531105273460682, 'recall_macro': 0.7279708041839421, 'recall_micro': 0.7573170731707317, 'recall_weighted': 0.7573170731707317, 'precision_macro': 0.7527270564328854, 'precision_micro': 0.7573170731707317, 'precision_weighted': 0.7526286151229844, 'classes': {0: {'precision': 0.9722222222222222, 'recall': 0.8898305084745762, 'f1': 0.9292035398230089, 'support': 118}, 1: {'precision': 0.7745358090185677, 'recall': 0.8613569321533924, 'f1': 0.8156424581005588, 'support': 339}, 2: {'precision': 0.746606334841629, 'recall': 0.7268722466960352, 'f1': 0.7366071428571428, 'support': 227}, 3: {'precision': 0.5175438596491229, 'recall': 0.4338235294117647, 'f1': 0.47200000000000003, 'support': 136}}}, metrics_median={'accuracy': 0.7573170731707317, 'f1_macro': 0.7383632851951776, 'f1_micro': 0.7573170731707317, 'f1_weighted': 0.7531105273460682, 'recall_macro': 0.7279708041839421, 'recall_micro': 0.7573170731707317, 'recall_weighted': 0.7573170731707317, 'precision_macro': 0.7527270564328854, 'precision_micro': 0.7573170731707317, 'precision_weighted': 0.7526286151229844, 'classes': {0: {'precision': 0.9722222222222222, 'recall': 0.8898305084745762, 'f1': 0.9292035398230089}, 1: {'precision': 0.7745358090185677, 'recall': 0.8613569321533924, 'f1': 0.8156424581005588}, 2: {'precision': 0.746606334841629, 'recall': 0.7268722466960352, 'f1': 0.7366071428571428}, 3: {'precision': 0.5175438596491229, 'recall': 0.4338235294117647, 'f1': 0.47200000000000003}}}, metrics_std={'accuracy': 0.0, 'f1_macro': 0.0, 'f1_micro': 0.0, 'f1_weighted': 0.0, 'recall_macro': 0.0, 'recall_micro': 0.0, 'recall_weighted': 0.0, 'precision_macro': 0.0, 'precision_micro': 0.0, 'precision_weighted': 0.0, 'classes': {0: {'precision': 0.0, 'recall': 0.0, 'f1': 0.0}, 1: {'precision': 0.0, 'recall': 0.0, 'f1': 0.0}, 2: {'precision': 0.0, 'recall': 0.0, 'f1': 0.0}, 3: {'precision': 0.0, 'recall': 0.0, 'f1': 0.0}}}, averaged_over=2)